Zendesk Service Incident Cause - June 25, 2024
What caused the Zendesk service incident on June 25, 2024?
The Zendesk service incident on June 25, 2024, was caused by an unexpected surge in HTTP requests. This surge led to a 'thundering herd' effect, overwhelming the Agent Graph server connections and causing readiness probes to fail. The Lotus component played a significant role by overloading the Ticket Data Manager (TDM) with multiple requests each time it reconnected. This was primarily due to conversation state subscriptions reconnecting after mass disconnections related to Zorg/Nginx and/or subscription service deployments. For more details, you can refer to the originalZendesk help article.
More related questions
How long did the Zendesk service disruptions last on June 25, 2024?
The service disruptions on June 25, 2024, typically lasted an average of 2 minutes. These disruptions occurred between 15:40 and 15:47 UTC, impacting customers across multiple pods. During this time, agents encountered 'Messages not found' errors…
What errors did Zendesk agents encounter during the June 2024 incident?
During the June 2024 incident, Zendesk agents encountered 'Messages not found' errors and 'Error code A_xxx' messages. These errors occurred when agents tried to load tickets in the Support Agent Workspace, disrupting their workflows and making it…
What measures did Zendesk take to resolve the June 2024 incident?
To resolve the June 2024 incident, Zendesk implemented several preventive measures. These included a Connection and Request Rate Limiter to regulate incoming traffic and steps to enhance the resilience of the Agent Graph during caching failures….
What are the future strategies to prevent Zendesk service disruptions?
Zendesk has planned several strategies to enhance system stability and prevent future disruptions. These include implementing a smoke test to alert the technical team about readiness probe failures, advising developers on fetching patterns,…
How did Zendesk ensure system stability after the June 2024 incident?
After the June 2024 incident, Zendesk made adjustments on July 10th to prevent request buildup issues, which successfully stabilized the system. By July 12th, performance had improved, and by July 15th, no further performance bumps or spikes were…
Interested indeflectingover 70% of your Zendesk support tickets?

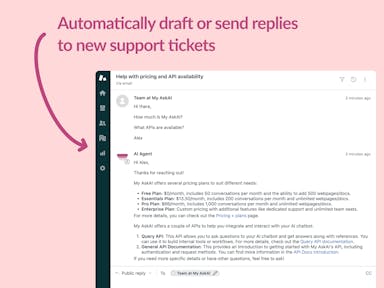
Zendesk Support Tickets
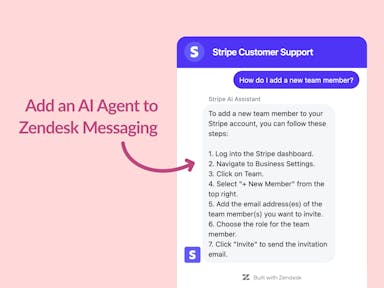
Zendesk Messaging (live chat)
Join1,000+ companies reducing their support costs and freeing up support agents for more important work
“We needed an AI agent integrated within our current tools. My AskAI was the only solution that wasn't going to disrupt our operations.”
Zeffy

“At the end of last year I was given the challenge - how can we provide the same or better service, without hiring anyone?”
Zinc
“My AskAI blew everybody else out of the water. It made the selection process very easy for us.”
Customer.io($50M+ ARR)

“It now resolves 71% of queries (over 35,000 every month), meaning more time solving complex issues and improving UX.”
Freecash

“We needed an AI agent integrated within our current tools. My AskAI was the only solution that wasn't going to disrupt our operations.”
Zeffy

“At the end of last year I was given the challenge - how can we provide the same or better service, without hiring anyone?”
Zinc

“My AskAI blew everybody else out of the water. It made the selection process very easy for us.”
Customer.io($50M+ ARR)
“It now resolves 71% of queries (over 35,000 every month), meaning more time solving complex issues and improving UX.”
Freecash







Reduce support costs.Spend more time on customer success.

