Why D_COUNT is Default in Zendesk Explore
Why is D_COUNT the default metric aggregator in Zendesk Explore?
D_COUNT is often the default metric aggregator in Zendesk Explore because it provides a unique count of items, which is generally more useful for accurate reporting.
For example, when counting the total number of tickets an agent has updated with a comment, using DCOUNT ensures that each ticket is counted only once, avoiding inflated numbers due to duplicates. While COUNT can be used for total counts, DCOUNT is preferred for unique counts, which is why it might be set as the default in some cases.
More related questions
What is the difference between COUNT and D_COUNT in Zendesk Explore?
COUNT and DCOUNT are both aggregation methods used in Zendesk Explore, but they serve different purposes. COUNT simply counts the total number of items in a dataset, while DCOUNT counts only the unique items. For example, if you have a list of…
When should I use D_COUNT instead of COUNT in Zendesk Explore?
You should use D_COUNT when you need to count only unique items in your dataset. This is particularly useful if you expect an item, like a ticket ID, to appear multiple times and you want to ensure it's only counted once. For instance, if you're…
How does COUNT and D_COUNT work with rows and columns in Zendesk reports?
In Zendesk reports, COUNT and D_COUNT are aggregated within each cell when attributes are placed in rows or columns, rather than for the report as a whole. For example, if you have tags like 'Cat', 'Dog', and 'Bird' across different tickets, COUNT…
Does using COUNT or D_COUNT affect counting rated satisfaction tickets?
In most cases, using COUNT or DCOUNT for rated satisfaction tickets in Zendesk Explore won't make a difference, as both will count the number of ticket IDs. However, if you're using a dataset like Ticket Updates and calculated metrics, DCOUNT…
Interested indeflectingover 70% of your Zendesk support tickets?

Zendesk Support Tickets
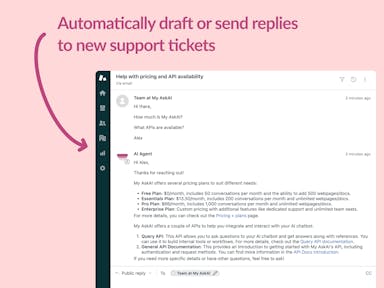
Zendesk Messaging (live chat)
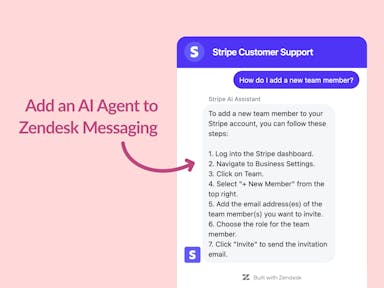
Join1,000+ companies reducing their support costs and freeing up support agents for more important work
“We needed an AI agent integrated within our current tools. My AskAI was the only solution that wasn't going to disrupt our operations.”
Zeffy

“At the end of last year I was given the challenge - how can we provide the same or better service, without hiring anyone?”
Zinc
“My AskAI blew everybody else out of the water. It made the selection process very easy for us.”
Customer.io($50M+ ARR)

“It now resolves 71% of queries (over 35,000 every month), meaning more time solving complex issues and improving UX.”
Freecash

“We needed an AI agent integrated within our current tools. My AskAI was the only solution that wasn't going to disrupt our operations.”
Zeffy

“At the end of last year I was given the challenge - how can we provide the same or better service, without hiring anyone?”
Zinc

“My AskAI blew everybody else out of the water. It made the selection process very easy for us.”
Customer.io($50M+ ARR)
“It now resolves 71% of queries (over 35,000 every month), meaning more time solving complex issues and improving UX.”
Freecash







Reduce support costs.Spend more time on customer success.

