Root Cause of Zendesk Incident on August 9, 2024
What caused the Zendesk service incident on August 9, 2024?
The incident on August 9, 2024, was caused by an unexpected reboot of a system that caches data in memory. This led to timeout errors and 503 service errors as the system failed to switch to an alternative data source promptly.
The monitors in place did not trigger alerts because the issue resolved itself before reaching alert thresholds. The system automatically recovered once the memory-caching system came back online, requiring no manual intervention.
More related questions
What happened during the Zendesk service incident on August 9, 2024?
On August 9, 2024, Zendesk experienced a service incident affecting Pod 17. From 15:46 UTC to 15:57 UTC, users faced issues such as error codes, slow loading times, and difficulties opening tickets or viewing messages. The incident was quickly…
How was the Zendesk service incident on August 9, 2024 resolved?
The Zendesk service incident on August 9, 2024, was resolved automatically as the memory-caching system came back online. The system's reboot caused delays, but it was self-resolving, so no immediate manual intervention was needed. To prevent…
What steps is Zendesk taking to prevent future incidents like the one on August 9, 2024?
To prevent future incidents similar to the one on August 9, 2024, Zendesk is implementing several measures. These include reducing the timeout for user cache retrieval, considering chaos testing to simulate failures, reviewing and adjusting alert…
Where can I find more information about the Zendesk incident on August 9, 2024?
For more information about the Zendesk incident on August 9, 2024, you can visit the Zendesk system status page. The post-mortem investigation summary is usually posted there a few days after the incident. If you have additional questions, you can…
Interested indeflectingover 70% of your Zendesk support tickets?

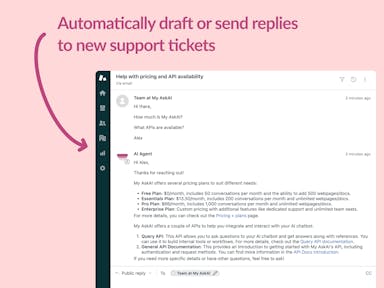
Zendesk Support Tickets
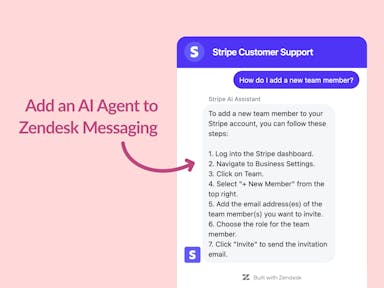
Zendesk Messaging (live chat)
Join1,000+ companies reducing their support costs and freeing up support agents for more important work
“We needed an AI agent integrated within our current tools. My AskAI was the only solution that wasn't going to disrupt our operations.”
Zeffy

“At the end of last year I was given the challenge - how can we provide the same or better service, without hiring anyone?”
Zinc
“My AskAI blew everybody else out of the water. It made the selection process very easy for us.”
Customer.io($50M+ ARR)

“It now resolves 71% of queries (over 35,000 every month), meaning more time solving complex issues and improving UX.”
Freecash

“We needed an AI agent integrated within our current tools. My AskAI was the only solution that wasn't going to disrupt our operations.”
Zeffy

“At the end of last year I was given the challenge - how can we provide the same or better service, without hiring anyone?”
Zinc

“My AskAI blew everybody else out of the water. It made the selection process very easy for us.”
Customer.io($50M+ ARR)
“It now resolves 71% of queries (over 35,000 every month), meaning more time solving complex issues and improving UX.”
Freecash







Reduce support costs.Spend more time on customer success.

