Remediation Steps for Zendesk Pod 13 SLA Incident
What were the remediation steps after the SLA badge incident in Pod 13?
Following the SLA badge incident in Pod 13, several remediation steps were taken. These included exploring better ways to organize and pass environment variables to ensure readiness during system restarts, improving the turnaround time for fixing broken SLAs by updating the 'funfiller', reviewing monitoring and alerts, and reinvestigating the method for passing environment variables to ensure their availability during system restarts.
More related questions
What caused the missing SLA badges on February 9, 2024, in Zendesk Pod 13?
The missing SLA badges on February 9, 2024, were due to a malfunction in one of the Kubernetes pods in Pod 13. This pod experienced an unplanned restart, which disrupted the 'redis' host, a critical component for the Metric Event Service (MES)….
How was the SLA badge issue resolved for Zendesk Pod 13?
The SLA badge issue for Zendesk Pod 13 was resolved by redeploying the malfunctioning Kubernetes pod. This action restored the missing SLA events, which were then backfilled. However, the backfill process inadvertently removed SLA data on closed…
What impact did the SLA badge issue have on closed tickets in Zendesk?
The SLA badge issue had a significant impact on closed tickets in Zendesk. During the resolution process, the backfill/restoration of data inadvertently removed SLA data on closed tickets, resulting in 'Null' SLA data in Explore. This was an…
Where can I find more information about Zendesk system incidents?
For more information about Zendesk system incidents, you can check the system status page. This page provides current system status information and usually includes a summary of post-mortem investigations a few days after an incident has ended. If…
Interested indeflectingover 70% of your Zendesk support tickets?

Zendesk Support Tickets
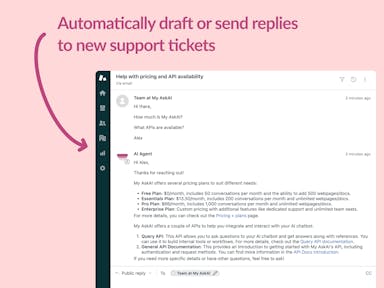
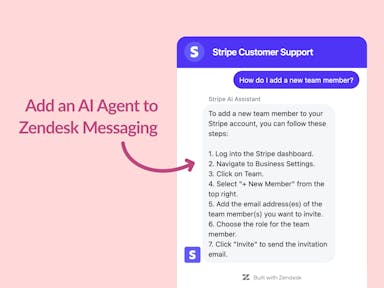
Zendesk Messaging (live chat)
Join1,000+ companies reducing their support costs and freeing up support agents for more important work
“We needed an AI agent integrated within our current tools. My AskAI was the only solution that wasn't going to disrupt our operations.”
Zeffy

“At the end of last year I was given the challenge - how can we provide the same or better service, without hiring anyone?”
Zinc
“My AskAI blew everybody else out of the water. It made the selection process very easy for us.”
Customer.io($50M+ ARR)

“It now resolves 71% of queries (over 35,000 every month), meaning more time solving complex issues and improving UX.”
Freecash

“We needed an AI agent integrated within our current tools. My AskAI was the only solution that wasn't going to disrupt our operations.”
Zeffy

“At the end of last year I was given the challenge - how can we provide the same or better service, without hiring anyone?”
Zinc

“My AskAI blew everybody else out of the water. It made the selection process very easy for us.”
Customer.io($50M+ ARR)
“It now resolves 71% of queries (over 35,000 every month), meaning more time solving complex issues and improving UX.”
Freecash







Reduce support costs.Spend more time on customer success.

